
A lot of what we do with our C-100 and C-200 decoders involves decoding MPEG-2 video which is still prevalent in spite of being over 25 years old.
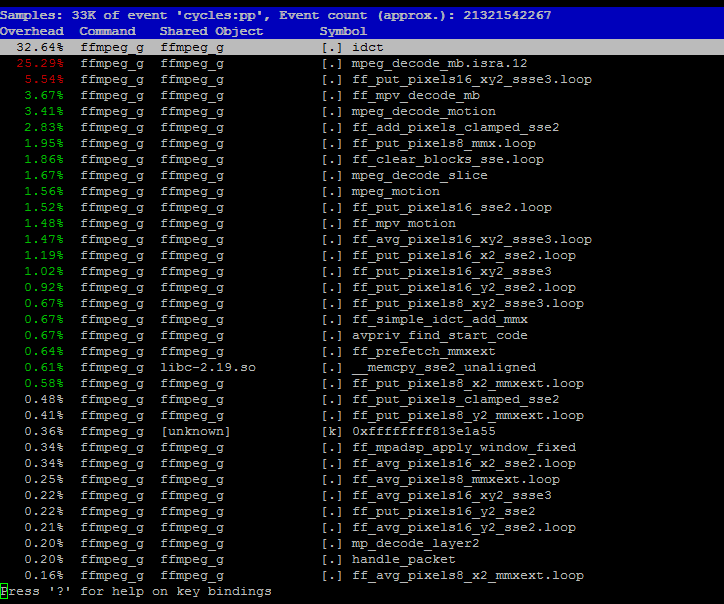
I was asked to improve the speed of the MPEG2 decoder in FFmpeg. A profile of decoding immediately showed that the IDCT was one of the hottest functions. This lead me to the simple_idct.c file and its long, old and rather complicated inline code. Reading it showed the the general layout of the code. It had several very long macros called a few times each to do the heavy lifting. Not a bad place to start the conversion from. I then cut out the the macros which contained the useful code and set about converting them.
I guess the first thing anyone needs to know is that gcc inline assembly is always in AT&T syntax whereas NASM uses Intel syntax. Although I think there is some option to let you use Intel syntax in gcc I have never seen it used. Dealing with this is the starting point to any conversion. To me everything is backwards.
Rather than mov dest, src what you get is mov src, dest. Instructions get size suffixes too, addl x, y and addw x, y rather than it being dictated by the register size you use. Worse still are the memory arguments which come in the form offset(base register, offset register, factor). I’m sure there is some legacy reason for this but I don’t know what that is.
Now this would be a good case to automate, or least have the computer help you with it. At the very least have it reverse the operands for you and deal with the other details yourself. If the assembly code was just for gas, (the GNU Assembler) then it wouldn’t be so bad and you could probably use a simple regex and sed, though memory arguments might be too much for that. Since this is inline code you have to deal with it all being in a C string and of course the C Preprocessor can be used. That isn’t so bad because NASM has one and a better one in my opinion.
It became obvious that I couldn’t just rotate around a comma to reverse the two operands because the code had many memory loads and stores. I thought of using Lua and its LPeg module. Being a complete newbie to LPeg I decided to use it as a line-based parser. I’m sure it can be made to parse the entire code in one go, break it down to its tokens, and then you can reassemble them as you need but that is beyond my current knowledge of it. For this reason I also won’t explain the LPeg concepts in too much detail.
The first thing to do was parse the macros. C macros have named parameters but NASM has numbered ones. When I encountered a line which began with #define I parsed the argument names given to make a lookup table and stored a line to define the NASM macro definition: %macro NAME num_args. Simple. Later with the lookup table I used a rather simplistic substitution like the C preprocessor. This was made easier by the fact that all the macro arguments had the stringify operator in front of them.
Before doing the macro parameter substitution another substitution needed to be made. The inline assembly block also takes arguments, roughly similar to function arguments. (Infact I was planning to use the function arguments here.) These are numbered from 0 with a percent sign prefix. Almost exactly like the NASM macro arguments which start from 1 but also have %0 representing the number of arguments. That’s why I had to do that substitution first.
The parser would work on those substituted lines. It would match the instruction, registers, immediates, memory arguments, and emit a table representing that, which I stored. I guess here is where I *should* explain a little more about LPeg for those unfamiliar with it.
Finally if LPeg couldn’t match the line with its pattern then I would store the unaltered line. Useful while writing it (you can see which lines it fails with) and at the end. There are about a half dozen lines which began with a C macro argument which I couldn’t be bothered to match with it. The argument was just a packed add double word instruction with a memory argument. I have no idea why it was written that way, it just was.
When a line didn’t end with a \ it signalled the end of the macro definition. When that was true I stored the %endmacro line.
After parsing I used the stored tables to recreate the code with a little nice formatting. If the stored value was just a string, I printed that. If the value was a table I pretty printed it to align operands and comments.
The rest of the conversion was done with a little copy-pasting and basic recreating of the various other components. There were some constants to define, and the main body to recreate. Constants are easy – NASM and x264asm will align the start of the read-only section, you just have to define your bytes (or other data sizes) and labels. Stack space is also pretty easy (at least with few function arguments). x264asm will align it for you, you just need to request the size you want when defining a function with the cglobal macro.
One thing I had to steal from another file was add/put clamped pixel macros. The old C code would call other functions to do this but that is somewhat harder to do in assembly. I don’t know how to, I’ve never had to do it. Fortunately these functions are already implemented in external NASM files so I just had to copy the relevant block to my new file and call it. Very simple.
Ultimately I don’t think it is hard converting inline to external assembly. Certainly FFmpeg’s use of it doesn’t make it that hard. Most of it is for DSP functions and they don’t usually call other functions. They don’t usually use too many branches other than loops. Mostly they are already vector/SIMD code. All you need is a reason to start it.
And here’s the patch: https://git.videolan.org/?p=ffmpeg.git;a=commitdiff;h=8e89f6fd37357361e0f4db5b6f3b422ce84175b0
In Part 2 learn about optimising the new code and handling the problems with the non-exact transform.
